
Open-Source AI Video Is Here: Helios & LTX 2.3 Change Everything
In the first two weeks of March 2026, two open-source AI video generation models dropped that fundamentally alter the competitive landscape of generative media. ByteDance's Helios — a 14-billion-parameter autoregressive diffusion model capable of generating 60-second videos at near real-time speed — and Lightricks' LTX 2.3 — a 19-billion-parameter dual-stream architecture delivering native 4K video with synchronized stereo audio — both shipped under the Apache 2.0 license. Production-quality AI video generation, the kind that required enterprise contracts and multi-GPU clusters six months ago, is now available to anyone with a capable GPU and an internet connection. This is not an incremental update. This is the moment open-source AI video generation reaches parity with closed-source commercial offerings, and in several measurable dimensions, surpasses them.
For creative teams, independent studios, and platform builders, the implications are immediate and practical. The cost structure of AI-generated video content just collapsed. The technical barriers to entry just fell. And the pace of community-driven innovation just accelerated dramatically. Here is what happened, what it means, and what you should do about it.
Helios: 60-Second Videos at Real-Time Speed
Helios emerged from a collaboration between ByteDance, Peking University, and Canva — an unusual trio that signals how open-source AI development increasingly bridges academic research, big tech infrastructure, and product-focused companies. Released on March 4, 2026, with the full codebase available on GitHub under PKU-YuanGroup/Helios, the model ships with three checkpoints: Base, Mid, and Distilled.
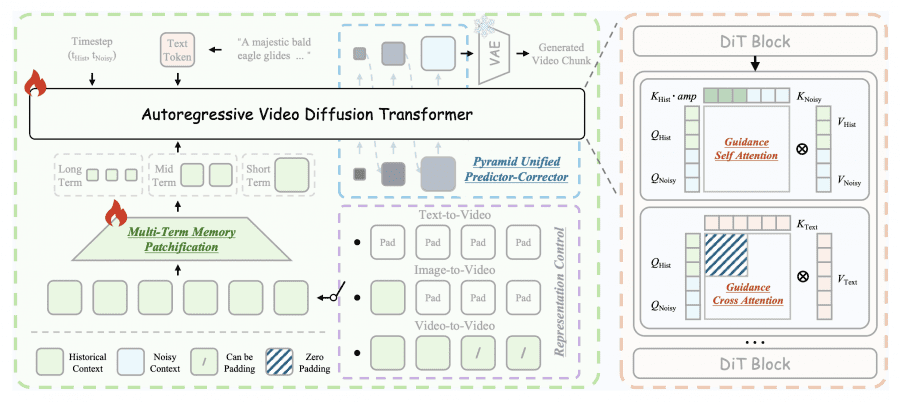
What Makes Helios Different
The headline number — up to 1,440 frames at 24 FPS, yielding roughly 60 seconds of continuous video — is impressive on its own. But the engineering choices underneath that number are what matter for practitioners.
Helios is built on two core innovations:
- Deep Compression Flow: A novel approach to latent space compression that dramatically reduces the computational cost per frame without sacrificing visual fidelity. This is how a 14B model generates video at 19.5 FPS on a single NVIDIA H100 GPU.
- Easy Anti-Drifting: A strategy that maintains temporal coherence across long sequences without relying on the usual bag of tricks — no KV-cache, no quantization hacks, no sparse attention, no anti-drifting heuristics. The architecture itself handles drift prevention natively.
That last point deserves emphasis. Most long-form video generation models accumulate artifacts and lose coherence past 10-15 seconds. Developers typically patch this with post-hoc techniques that add complexity, reduce speed, and introduce their own failure modes. Helios sidesteps the entire problem architecturally.
Unified Input Pipeline
Helios handles text-to-video, image-to-video, and video-to-video through a single unified input interface. You do not need separate model variants or specialized pipelines for different generation modes. Feed it a text prompt, a reference image, or an existing video clip, and the same model processes all three.
This matters for production workflows. A unified pipeline means fewer moving parts, simpler deployment, and more predictable behavior across use cases.
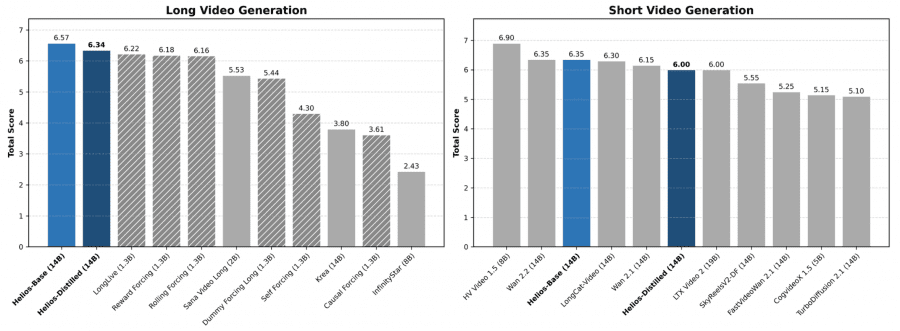
Performance That Matters
The throughput numbers tell the real story:
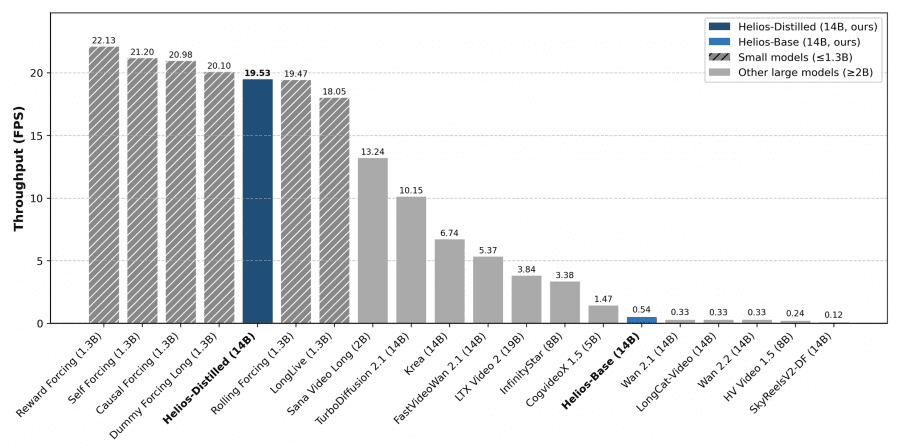
- 19.5 FPS generation speed on a single NVIDIA H100 GPU
- 60 seconds of continuous video per generation (1,440 frames at 24 FPS)
- Three checkpoint options allowing teams to trade quality for speed depending on use case
The Distilled checkpoint, in particular, opens doors for teams running on consumer-grade hardware or constrained cloud budgets. It is not H100-or-nothing — though that is where peak performance lives.
"The absence of KV-cache and quantization heuristics in Helios is not a limitation — it is a design statement. The architecture does not need them."
LTX 2.3: Native 4K With Synchronized Audio
If Helios is about duration and speed, LTX 2.3 is about fidelity and completeness. Lightricks — the company behind Facetune and a growing suite of AI creative tools — released LTX 2.3 as the first open-source model that delivers true 4K resolution with native stereo audio generation in a single pipeline.

Architecture and Capabilities
LTX 2.3 is a 19-billion-parameter model, split across a 14B video component and a 5B audio component. The two streams are bound together through bidirectional cross-attention, which means audio and video are not generated independently and then stitched together. They are generated in mutual awareness of each other — the audio influences the video, and the video influences the audio, at every step of the diffusion process.
Key specifications:
| Feature | LTX 2.3 |
|---|---|
| Total parameters | 19B (14B video + 5B audio) |
| Maximum resolution | Native 4K |
| Frame rate | Up to 50 FPS (24/48 FPS standard) |
| Maximum duration | 20 seconds per clip |
| Audio | Native stereo, synchronized via cross-attention |
| Aspect ratios | Landscape, portrait (9:16), square |
| Speed vs. Wan 2.2 | 18x faster |
| VAE | New architecture for sharper detail reproduction |
| License | Apache 2.0 |
Why Audio Changes Everything
Previous open-source video models generated silent video. Adding audio was a separate step — typically involving a different model, a different pipeline, and a manual synchronization process that frequently produced uncanny results. Lips moved out of sync with speech. Sound effects arrived a beat too late. The "last mile" of audio-video alignment consumed as much production time as the initial generation.
LTX 2.3 eliminates this entire workflow. The dual-stream architecture with bidirectional cross-attention means that when you generate a video of rain hitting a window, the sound of rain is generated simultaneously, at the correct intensity, with the correct spatial characteristics. When a character speaks, the lip movements and the speech audio are co-generated.
"LTX 2.3 is not a video model with audio bolted on. It is an audiovisual generation system. That distinction matters more than any resolution spec."
The Speed Factor
Being 18 times faster than Wan 2.2 — a model many production teams have been using as their open-source baseline — makes LTX 2.3 not just technically superior but practically viable for iterative creative workflows. At 18x speed improvement, what previously took 30 minutes of generation time now takes under 2 minutes. That is the difference between "generate and wait" and "generate, review, adjust, regenerate" within a single creative session.
LTX Desktop: Local Generation for Everyone
Lightricks also released LTX Desktop, an open-source desktop application that wraps the LTX 2.3 model in a user-friendly interface for local generation. This is significant because it removes the need for command-line expertise, Python environment management, or cloud API integration. Download, install, generate.
For teams already exploring local AI video generation workflows, this pairs naturally with the NVIDIA RTX + ComfyUI ecosystem we covered in our analysis of local 4K AI video generation.
Head-to-Head: Helios vs. LTX 2.3
These models are not direct competitors so much as they are complementary tools optimized for different production needs. Here is how they compare:
| Dimension | Helios | LTX 2.3 |
|---|---|---|
| Parameters | 14B | 19B (14B video + 5B audio) |
| Max duration | ~60 seconds (1,440 frames) | 20 seconds |
| Max resolution | HD | Native 4K |
| Max FPS | 24 | 50 |
| Audio | No native audio | Native stereo (5B audio model) |
| Generation speed | 19.5 FPS on H100 | 18x faster than Wan 2.2 |
| Input modes | Text, image, video (unified) | Text-to-video |
| Architecture | Autoregressive diffusion | Dual-stream cross-attention |
| Anti-drift | Native (Easy Anti-Drifting) | Standard techniques |
| Desktop app | No | Yes (LTX Desktop) |
| License | Apache 2.0 | Apache 2.0 |
| Best for | Long-form content, narrative sequences | High-fidelity short clips, audiovisual content |
The decision framework is straightforward:
- Need videos longer than 20 seconds with consistent temporal coherence? Helios.
- Need 4K resolution with synchronized audio in a single pipeline? LTX 2.3.
- Building a production pipeline that needs both? Use both. They are both Apache 2.0.
What This Means for the Industry
The Cost Collapse
Six months ago, generating production-quality AI video at scale required either an enterprise contract with a closed-source provider (Runway, Pika, Sora) or a substantial cloud GPU budget running earlier open-source models that were slower and lower quality. The per-minute cost of AI-generated video was measured in dollars, sometimes tens of dollars.
With Helios and LTX 2.3, the marginal cost of generation drops to GPU compute time alone. For teams with existing H100 access, Helios generates at near real-time speed — meaning the cost per minute of generated video approaches the cost per minute of GPU rental. For LTX 2.3 on consumer hardware via LTX Desktop, the cost is effectively zero beyond the initial hardware investment.
This cost collapse does not just make existing workflows cheaper. It enables entirely new categories of content that were previously uneconomical — AI-generated background footage, procedural animation for games, personalized video at scale, synthetic training data for computer vision.
The Quality Threshold
Both models cross what we might call the "production quality threshold" — the point at which generated video is good enough for professional use without extensive post-processing. Helios achieves this through temporal coherence over long durations. LTX 2.3 achieves it through resolution fidelity and audiovisual synchronization.
This is the same threshold that text-to-image models crossed in late 2022 with Stable Diffusion, and the consequences were seismic. Creative industries restructured. New product categories emerged. Pricing models for stock photography and illustration services collapsed. The same pattern is now beginning for video.
For a broader view of how these models fit into the current landscape of AI video tools — both open and closed source — see our comprehensive comparison of the best AI video generators in 2026.
The Open-Source Acceleration
Both models shipping under Apache 2.0 means the community can fine-tune, distill, merge, and build on top of them without legal constraints. History shows what happens next:
- Community fine-tunes appear within weeks, optimized for specific styles, domains, or hardware configurations
- Integration into existing tools like ComfyUI, A1111, and emerging workflow platforms accelerates
- Derivative models combine innovations from both architectures
- Hardware vendors optimize their stacks for these specific architectures (NVIDIA's GDC announcements around ComfyUI are not coincidental)
- Commercial products build differentiated UX, curation, and workflow features on top of the open models
This is the flywheel that made Stable Diffusion the backbone of an entire ecosystem. It is now spinning for video.
March 2026 also saw NVIDIA's ComfyUI integration updates at GDC, the Qwen 3.5 Small family release, and GPT-5.4's launch. The AI infrastructure is maturing across every modality simultaneously. Open-source video generation is not happening in isolation — it is part of a broader shift toward accessible, production-grade AI tools.
The ByteDance Factor
It is worth noting that ByteDance is behind both Helios and the previously released Seedance 2.0, which made waves in the entertainment industry. ByteDance's strategy is becoming clear: release state-of-the-art models as open source, build ecosystem gravity, and monetize through platform integration rather than model access.
This is the same playbook Meta ran with Llama for language models. It worked. ByteDance is now running it for video, and with Helios's performance characteristics, it is likely to work again.
What You Should Do About It
If You Are a Creative Team or Studio
- Download and test both models now. The Apache 2.0 license means zero risk in evaluation. Start with LTX Desktop if you want the fastest path to hands-on experience.
- Identify your highest-volume video production workflows and assess which segments could be partially or fully automated. Background footage, B-roll, motion graphics backgrounds, and product visualization are immediate candidates.
- Budget for GPU infrastructure. Whether cloud-based H100 access for Helios or local RTX hardware for LTX 2.3, the capital expenditure pays for itself quickly at production volumes.
If You Are Building a Product or Platform
- Evaluate integration immediately. Both models are Apache 2.0, meaning you can embed them in commercial products without licensing fees.
- Focus your differentiation on workflow, not generation. The generation capability is now commodity. The value is in the creative workflow around it — curation, editing, iteration, collaboration, brand consistency.
- Consider multi-model pipelines. Helios for long-form sequences, LTX 2.3 for high-fidelity hero shots with audio, stitched together in a unified workflow.
If You Are Watching From the Sidelines
- The window for "wait and see" is closing. Open-source AI video generation is now production-ready. Early adopters will build institutional knowledge and workflow expertise that compounds over time.
- Start with a low-stakes project. Use AI video for internal presentations, social media content, or prototype visualization before committing to client-facing production work.
XainFlow's Flow Studio lets you build visual AI pipelines that can orchestrate multiple models — including open-source video generators — in a single drag-and-drop canvas. It is designed for exactly the kind of multi-model workflows that Helios and LTX 2.3 enable.
The Bottom Line
Open-source AI video generation just had its "Stable Diffusion moment." Helios brings 60-second coherent video generation at real-time speed. LTX 2.3 brings native 4K with synchronized audio. Both are Apache 2.0. Both run on accessible hardware. Both are production-ready today.
The question is no longer whether open-source AI video models can compete with closed-source alternatives. They can. In duration (Helios) and audiovisual fidelity (LTX 2.3), they already lead. The question is now how quickly creative teams, studios, and platform builders will retool their workflows to capitalize on what is freely available.
The models are here. The licenses are permissive. The performance is real. The only remaining variable is execution — and that part is up to you.


