
El Video con IA Open Source Ya Está Aquí: Helios y LTX 2.3 Lo Cambian Todo
En las dos primeras semanas de marzo de 2026, dos modelos open source de generación de video con IA aparecieron y alteraron fundamentalmente el panorama competitivo de los medios generativos. Helios de ByteDance — un modelo de difusión autoregresiva de 14 mil millones de parámetros capaz de generar videos de 60 segundos a velocidad casi en tiempo real — y LTX 2.3 de Lightricks — una arquitectura de doble flujo de 19 mil millones de parámetros que entrega video nativo en 4K con audio estéreo sincronizado — ambos publicados bajo la licencia Apache 2.0. La generación de video con IA de calidad profesional, esa que hace seis meses requería contratos empresariales y clústeres multi-GPU, ahora está disponible para cualquiera con una GPU capaz y conexión a internet. Esto no es una actualización incremental. Este es el momento en que la generación de video con IA open source alcanza la paridad con las ofertas comerciales de código cerrado, y en varias dimensiones medibles, las supera.
Para equipos creativos, estudios independientes y desarrolladores de plataformas, las implicaciones son inmediatas y prácticas. La estructura de costos del contenido de video generado por IA acaba de colapsar. Las barreras técnicas de entrada acaban de caer. Y el ritmo de innovación impulsado por la comunidad acaba de acelerarse dramáticamente. Esto es lo que pasó, lo que significa y lo que deberías hacer al respecto.
Helios: Videos de 60 Segundos a Velocidad en Tiempo Real
Helios surgió de una colaboración entre ByteDance, la Universidad de Pekín y Canva — un trío inusual que señala cómo el desarrollo de IA open source conecta cada vez más la investigación académica, la infraestructura de las grandes tecnológicas y las empresas orientadas a producto. Lanzado el 4 de marzo de 2026, con el código completo disponible en GitHub bajo PKU-YuanGroup/Helios, el modelo viene con tres checkpoints: Base, Mid y Distilled.
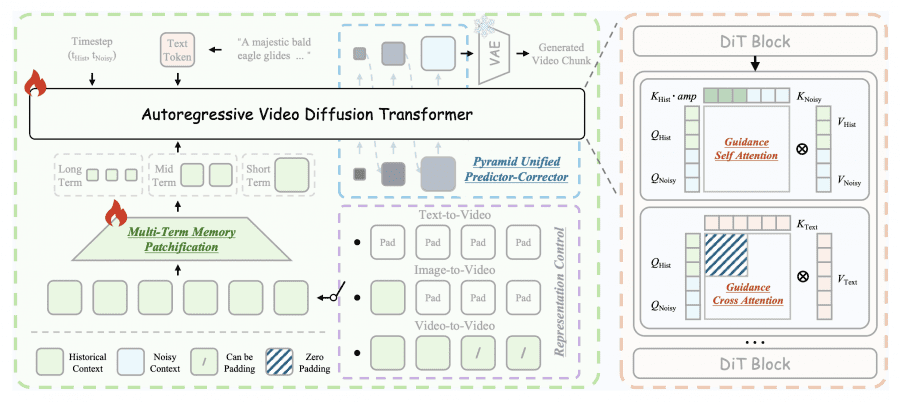
Qué Hace Diferente a Helios
La cifra destacada — hasta 1.440 frames a 24 FPS, generando aproximadamente 60 segundos de video continuo — es impresionante por sí sola. Pero las decisiones de ingeniería detrás de esa cifra son lo que importa para los profesionales.
Helios está construido sobre dos innovaciones clave:
- Deep Compression Flow: Un enfoque novedoso de compresión del espacio latente que reduce drásticamente el costo computacional por frame sin sacrificar la fidelidad visual. Así es como un modelo de 14B genera video a 19.5 FPS en una sola GPU NVIDIA H100.
- Easy Anti-Drifting: Una estrategia que mantiene la coherencia temporal a lo largo de secuencias extensas sin recurrir a los trucos habituales — sin KV-cache, sin hacks de cuantización, sin atención dispersa, sin heurísticas anti-drift. La propia arquitectura maneja la prevención de drift de forma nativa.
Ese último punto merece énfasis. La mayoría de los modelos de generación de video de larga duración acumulan artefactos y pierden coherencia después de 10-15 segundos. Los desarrolladores suelen parchear esto con técnicas post-hoc que añaden complejidad, reducen la velocidad e introducen sus propios modos de fallo. Helios evita todo el problema arquitectónicamente.
Pipeline de Entrada Unificado
Helios maneja texto-a-video, imagen-a-video y video-a-video a través de una única interfaz de entrada unificada. No necesitas variantes de modelo separadas ni pipelines especializados para diferentes modos de generación. Aliméntalo con un prompt de texto, una imagen de referencia o un clip de video existente, y el mismo modelo procesa los tres.
Esto importa para los flujos de trabajo de producción. Un pipeline unificado significa menos piezas en movimiento, despliegue más simple y comportamiento más predecible entre casos de uso.
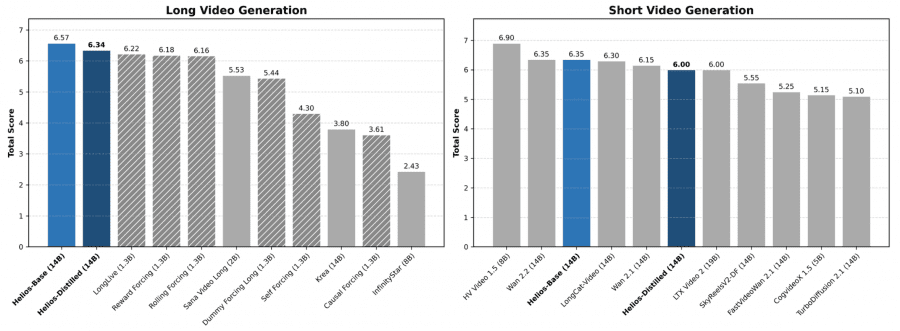
Rendimiento Que Importa
Las cifras de throughput cuentan la verdadera historia:
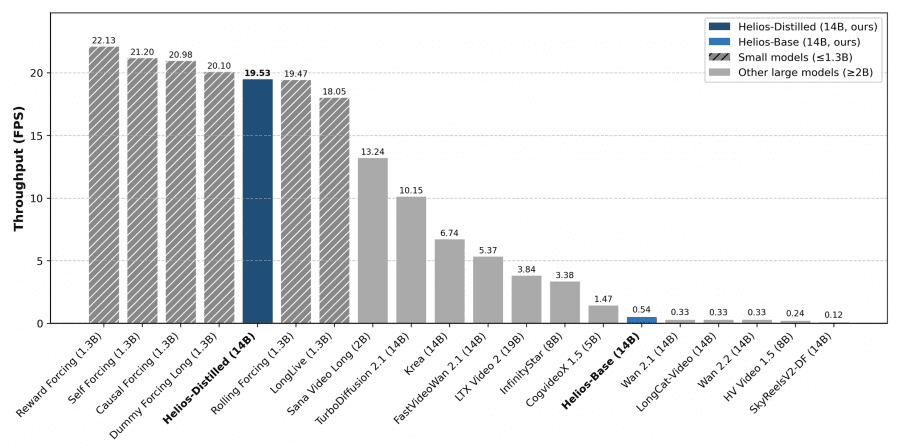
- 19.5 FPS de velocidad de generación en una sola GPU NVIDIA H100
- 60 segundos de video continuo por generación (1.440 frames a 24 FPS)
- Tres opciones de checkpoint que permiten a los equipos intercambiar calidad por velocidad según el caso de uso
El checkpoint Distilled, en particular, abre puertas para equipos que trabajan con hardware de consumo o presupuestos limitados en la nube. No es H100 o nada — aunque ahí es donde vive el rendimiento máximo.
"La ausencia de KV-cache y heurísticas de cuantización en Helios no es una limitación — es una declaración de diseño. La arquitectura no las necesita."
LTX 2.3: 4K Nativo Con Audio Sincronizado
Si Helios trata sobre duración y velocidad, LTX 2.3 trata sobre fidelidad y completitud. Lightricks — la empresa detrás de Facetune y una creciente suite de herramientas creativas con IA — lanzó LTX 2.3 como el primer modelo open source que entrega resolución 4K real con generación de audio estéreo nativo en un solo pipeline.

Arquitectura y Capacidades
LTX 2.3 es un modelo de 19 mil millones de parámetros, dividido entre un componente de video de 14B y un componente de audio de 5B. Los dos flujos están vinculados mediante atención cruzada bidireccional, lo que significa que el audio y el video no se generan de forma independiente para luego unirlos. Se generan con consciencia mutua — el audio influye en el video, y el video influye en el audio, en cada paso del proceso de difusión.
Especificaciones clave:
| Característica | LTX 2.3 |
|---|---|
| Parámetros totales | 19B (14B video + 5B audio) |
| Resolución máxima | 4K nativo |
| Tasa de frames | Hasta 50 FPS (24/48 FPS estándar) |
| Duración máxima | 20 segundos por clip |
| Audio | Estéreo nativo, sincronizado vía atención cruzada |
| Relaciones de aspecto | Horizontal, vertical (9:16), cuadrado |
| Velocidad vs. Wan 2.2 | 18x más rápido |
| VAE | Nueva arquitectura para reproducción de detalles más nítidos |
| Licencia | Apache 2.0 |
Por Qué el Audio Lo Cambia Todo
Los modelos open source de video anteriores generaban video sin sonido. Añadir audio era un paso separado — que típicamente involucraba un modelo diferente, un pipeline diferente y un proceso de sincronización manual que frecuentemente producía resultados inquietantes. Los labios se movían fuera de sincronía con el habla. Los efectos de sonido llegaban un instante tarde. La "última milla" de la alineación audio-video consumía tanto tiempo de producción como la generación inicial.
LTX 2.3 elimina todo este flujo de trabajo. La arquitectura de doble flujo con atención cruzada bidireccional significa que cuando generas un video de lluvia golpeando una ventana, el sonido de la lluvia se genera simultáneamente, con la intensidad correcta, con las características espaciales correctas. Cuando un personaje habla, los movimientos de labios y el audio del habla se co-generan.
"LTX 2.3 no es un modelo de video con audio añadido encima. Es un sistema de generación audiovisual. Esa distinción importa más que cualquier especificación de resolución."
El Factor Velocidad
Ser 18 veces más rápido que Wan 2.2 — un modelo que muchos equipos de producción han estado usando como su línea base open source — hace que LTX 2.3 no solo sea técnicamente superior sino prácticamente viable para flujos de trabajo creativos iterativos. Con una mejora de velocidad de 18x, lo que antes tomaba 30 minutos de tiempo de generación ahora toma menos de 2 minutos. Esa es la diferencia entre "generar y esperar" y "generar, revisar, ajustar, regenerar" dentro de una sola sesión creativa.
LTX Desktop: Generación Local para Todos
Lightricks también lanzó LTX Desktop, una aplicación de escritorio open source que envuelve el modelo LTX 2.3 en una interfaz amigable para generación local. Esto es significativo porque elimina la necesidad de experiencia en línea de comandos, gestión de entornos Python o integración con APIs en la nube. Descargar, instalar, generar.
Para equipos que ya están explorando flujos de trabajo de generación local de video con IA, esto se combina naturalmente con el ecosistema NVIDIA RTX + ComfyUI que cubrimos en nuestro análisis de generación local de video 4K con IA.
Cara a Cara: Helios vs. LTX 2.3
Estos modelos no son competidores directos tanto como herramientas complementarias optimizadas para diferentes necesidades de producción. Así se comparan:
| Dimensión | Helios | LTX 2.3 |
|---|---|---|
| Parámetros | 14B | 19B (14B video + 5B audio) |
| Duración máxima | ~60 segundos (1.440 frames) | 20 segundos |
| Resolución máxima | HD | 4K nativo |
| FPS máximos | 24 | 50 |
| Audio | Sin audio nativo | Estéreo nativo (modelo de audio 5B) |
| Velocidad de generación | 19.5 FPS en H100 | 18x más rápido que Wan 2.2 |
| Modos de entrada | Texto, imagen, video (unificado) | Texto-a-video |
| Arquitectura | Difusión autoregresiva | Atención cruzada de doble flujo |
| Anti-drift | Nativo (Easy Anti-Drifting) | Técnicas estándar |
| App de escritorio | No | Sí (LTX Desktop) |
| Licencia | Apache 2.0 | Apache 2.0 |
| Ideal para | Contenido de larga duración, secuencias narrativas | Clips cortos de alta fidelidad, contenido audiovisual |
El marco de decisión es sencillo:
- ¿Necesitas videos de más de 20 segundos con coherencia temporal consistente? Helios.
- ¿Necesitas resolución 4K con audio sincronizado en un solo pipeline? LTX 2.3.
- ¿Construyendo un pipeline de producción que necesita ambos? Usa ambos. Los dos son Apache 2.0.
Qué Significa Esto para la Industria
El Colapso de Costos
Hace seis meses, generar video con IA de calidad profesional a escala requería un contrato empresarial con un proveedor de código cerrado (Runway, Pika, Sora) o un presupuesto sustancial de GPU en la nube ejecutando modelos open source anteriores que eran más lentos y de menor calidad. El costo por minuto de video generado por IA se medía en dólares, a veces decenas de dólares.
Con Helios y LTX 2.3, el costo marginal de generación se reduce al tiempo de cómputo GPU únicamente. Para equipos con acceso existente a H100, Helios genera a velocidad casi en tiempo real — lo que significa que el costo por minuto de video generado se acerca al costo por minuto de alquiler de GPU. Para LTX 2.3 en hardware de consumo vía LTX Desktop, el costo es efectivamente cero más allá de la inversión inicial en hardware.
Este colapso de costos no solo hace más baratos los flujos de trabajo existentes. Habilita categorías completamente nuevas de contenido que antes eran antieconómicas — metraje de fondo generado por IA, animación procedural para videojuegos, video personalizado a escala, datos de entrenamiento sintéticos para visión por computadora.
El Umbral de Calidad
Ambos modelos cruzan lo que podríamos llamar el "umbral de calidad profesional" — el punto en el que el video generado es lo suficientemente bueno para uso profesional sin post-procesamiento extensivo. Helios lo logra mediante coherencia temporal en duraciones largas. LTX 2.3 lo logra mediante fidelidad de resolución y sincronización audiovisual.
Este es el mismo umbral que los modelos de texto-a-imagen cruzaron a finales de 2022 con Stable Diffusion, y las consecuencias fueron sísmicas. Las industrias creativas se reestructuraron. Surgieron nuevas categorías de productos. Los modelos de precios para fotografía de stock y servicios de ilustración colapsaron. El mismo patrón está comenzando ahora para el video.
Para una visión más amplia de cómo estos modelos encajan en el panorama actual de herramientas de video con IA — tanto open source como de código cerrado — consulta nuestra comparación completa de los mejores generadores de video con IA en 2026.
La Aceleración Open Source
Que ambos modelos se publiquen bajo Apache 2.0 significa que la comunidad puede hacer fine-tuning, destilación, fusión y construir sobre ellos sin restricciones legales. La historia muestra lo que sucede después:
- Fine-tunes de la comunidad aparecen en semanas, optimizados para estilos específicos, dominios o configuraciones de hardware
- Integración en herramientas existentes como ComfyUI, A1111 y plataformas emergentes de workflow se acelera
- Modelos derivados combinan innovaciones de ambas arquitecturas
- Fabricantes de hardware optimizan sus stacks para estas arquitecturas específicas (los anuncios de NVIDIA en GDC alrededor de ComfyUI no son coincidencia)
- Productos comerciales construyen UX diferenciada, curación y funcionalidades de workflow sobre los modelos abiertos
Este es el efecto volante que convirtió a Stable Diffusion en la columna vertebral de todo un ecosistema. Ahora está girando para el video.
Marzo de 2026 también trajo las actualizaciones de integración de ComfyUI por parte de NVIDIA en GDC, el lanzamiento de la familia Qwen 3.5 Small y el lanzamiento de GPT-5.4. La infraestructura de IA está madurando en todas las modalidades simultáneamente. La generación de video open source no está ocurriendo de forma aislada — es parte de un cambio más amplio hacia herramientas de IA accesibles y de calidad profesional.
El Factor ByteDance
Vale la pena señalar que ByteDance está detrás tanto de Helios como del previamente lanzado Seedance 2.0, que generó revuelo en la industria del entretenimiento. La estrategia de ByteDance se está volviendo clara: lanzar modelos de última generación como open source, construir gravedad de ecosistema y monetizar a través de la integración en plataformas en lugar del acceso al modelo.
Este es el mismo playbook que Meta ejecutó con Llama para modelos de lenguaje. Funcionó. ByteDance ahora lo está ejecutando para video, y con las características de rendimiento de Helios, es probable que funcione de nuevo.
Qué Deberías Hacer al Respecto
Si Eres un Equipo Creativo o Estudio
- Descarga y prueba ambos modelos ahora. La licencia Apache 2.0 significa cero riesgo en la evaluación. Comienza con LTX Desktop si quieres el camino más rápido a la experiencia práctica.
- Identifica tus flujos de trabajo de producción de video de mayor volumen y evalúa qué segmentos podrían ser parcial o totalmente automatizados. Metraje de fondo, B-roll, fondos de motion graphics y visualización de productos son candidatos inmediatos.
- Presupuesta para infraestructura GPU. Ya sea acceso a H100 en la nube para Helios o hardware RTX local para LTX 2.3, la inversión de capital se amortiza rápidamente a volúmenes de producción.
Si Estás Construyendo un Producto o Plataforma
- Evalúa la integración inmediatamente. Ambos modelos son Apache 2.0, lo que significa que puedes integrarlos en productos comerciales sin tarifas de licencia.
- Enfoca tu diferenciación en el workflow, no en la generación. La capacidad de generación es ahora commodity. El valor está en el flujo de trabajo creativo alrededor de ella — curación, edición, iteración, colaboración, consistencia de marca.
- Considera pipelines multi-modelo. Helios para secuencias de larga duración, LTX 2.3 para tomas hero de alta fidelidad con audio, unidos en un workflow unificado.
Si Estás Observando Desde la Barrera
- La ventana para "esperar y ver" se está cerrando. La generación de video con IA open source ya está lista para producción. Los adoptantes tempranos construirán conocimiento institucional y experiencia en flujos de trabajo que se acumula con el tiempo.
- Comienza con un proyecto de bajo riesgo. Usa video con IA para presentaciones internas, contenido de redes sociales o visualización de prototipos antes de comprometerte con trabajo de producción para clientes.
El Flow Studio de XainFlow te permite construir pipelines visuales de IA que pueden orquestar múltiples modelos — incluyendo generadores de video open source — en un solo canvas de arrastrar y soltar. Está diseñado exactamente para el tipo de workflows multi-modelo que Helios y LTX 2.3 hacen posibles.
La Conclusión
La generación de video con IA open source acaba de tener su "momento Stable Diffusion". Helios trae generación de video coherente de 60 segundos a velocidad en tiempo real. LTX 2.3 trae 4K nativo con audio sincronizado. Ambos son Apache 2.0. Ambos funcionan en hardware accesible. Ambos están listos para producción hoy.
La pregunta ya no es si los modelos open source de video con IA pueden competir con las alternativas de código cerrado. Pueden. En duración (Helios) y fidelidad audiovisual (LTX 2.3), ya lideran. La pregunta ahora es qué tan rápido los equipos creativos, estudios y desarrolladores de plataformas reconfigurarán sus flujos de trabajo para capitalizar lo que está disponible gratuitamente.
Los modelos están aquí. Las licencias son permisivas. El rendimiento es real. La única variable restante es la ejecución — y esa parte depende de ti.


