
NVIDIA RTX + ComfyUI: El Video IA Local en 4K Ya Es Realidad
Durante años, generar video IA de alta calidad significaba depender de plataformas en la nube — subir prompts, esperar en colas y pagar tarifas por segundo que se acumulaban rápido. Esa era está terminando. En el CES 2026, NVIDIA anunció una ola de optimizaciones que llevan la generación de video IA en 4K de calidad profesional a GPUs RTX de consumo, impulsada por el modelo de código abierto LTX-2 y un pipeline de ComfyUI profundamente optimizado.
Para equipos creativos y agencias que producen contenido de video a escala, este cambio de la nube a lo local transforma la economía — y las posibilidades creativas — de la producción de video IA por completo.
Si has estado observando el video IA desde la barrera esperando a que se volviera práctico, este es el momento de prestar atención.
Qué Cambió: LTX-2 Encuentra al Hardware RTX
La pieza central de este anuncio es LTX-2, un modelo de audio-video de pesos abiertos de Lightricks que genera clips de hasta resolución 4K, 50 FPS y 20 segundos de duración. A diferencia de modelos locales anteriores que producían resultados borrosos e inconsistentes, LTX-2 ofrece una calidad que rivaliza con servicios en la nube como Runway y Sora.
Lo especial de LTX-2 no es solo la calidad — es la arquitectura. El modelo genera sincrónicamente movimiento, diálogo, ruido de fondo y música en un solo pase. Sin pipeline de audio separado, sin dolores de cabeza de post-sincronización. Un prompt, un clip coherente.
"LTX-2 ofrece resultados que compiten cara a cara con los principales modelos basados en la nube — mientras se ejecuta completamente en tu GPU local."
Soporta entradas multimodales: prompts de texto, imágenes de referencia, clips de audio, mapas de profundidad e incluso video de referencia para un control creativo preciso. Para agencias que necesitan estéticas de marca consistentes a través de múltiples clips, este nivel de control es revolucionario.
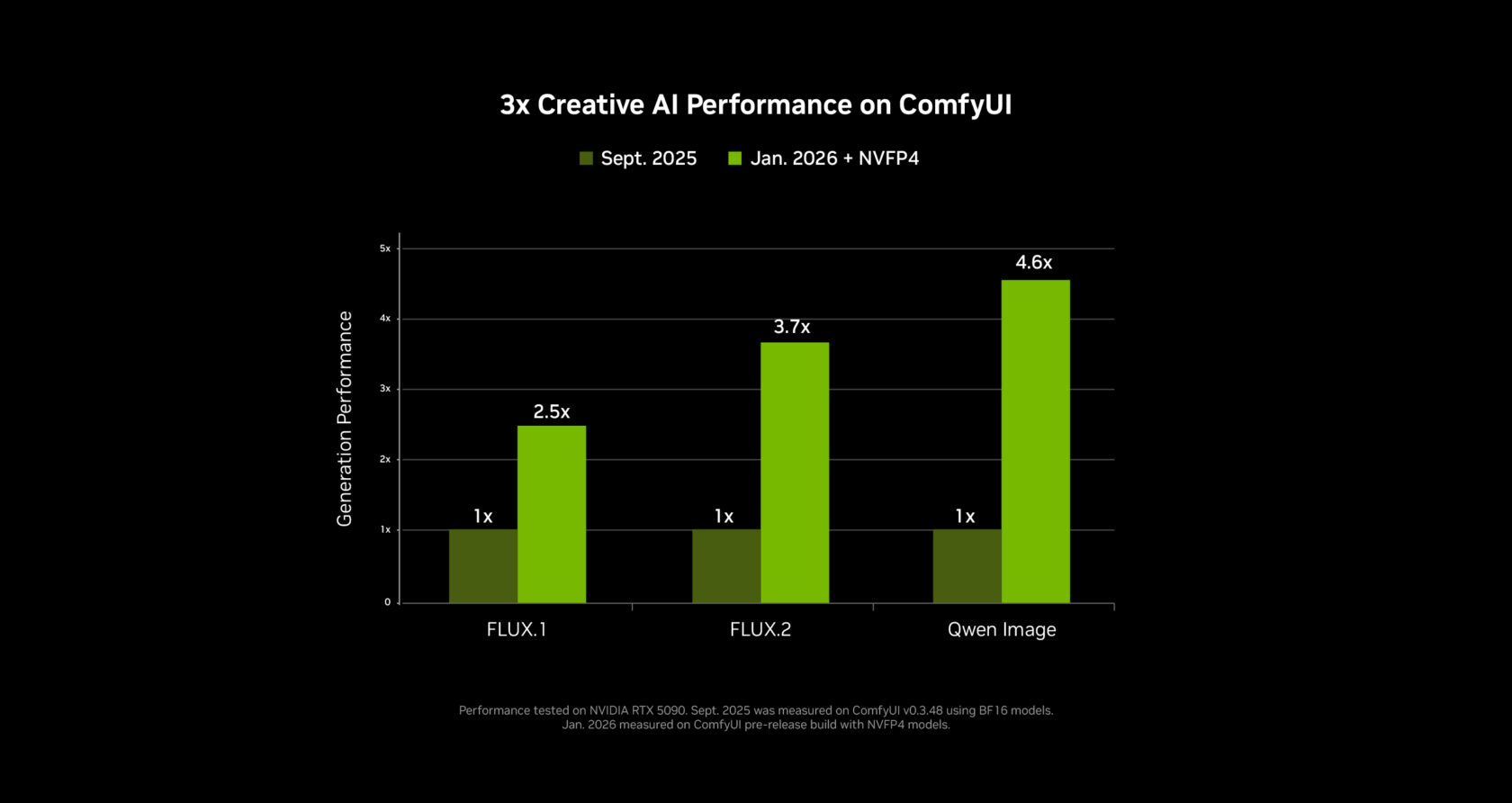
Los Números: 3x Más Rápido, 60% Menos VRAM
NVIDIA no solo lanzó un nuevo modelo — rediseñaron todo el pipeline. Trabajando estrechamente con el equipo de ComfyUI, entregaron:
| Optimización | Ganancia de Rendimiento | Reducción de VRAM |
|---|---|---|
| NVFP4 (Serie RTX 50) | 3x más rápido | 60% menos |
| NVFP8 (Serie RTX 40) | 2x más rápido | 40% menos |
| Optimizaciones core de ComfyUI | 40% más rápido | — |
Estos no son benchmarks teóricos. En una GeForce RTX 5090 (32GB VRAM), un clip de 720p de 4 segundos a 24fps se genera en aproximadamente 25 segundos. Clips más largos de 8 segundos tardan alrededor de tres minutos mientras el sistema activa el streaming de pesos para usar la RAM del sistema más allá del límite de memoria de la GPU.
Incluso GPUs de gama media con 12-16GB de VRAM pueden ejecutar LTX-2 eficazmente. Usa resolución 540p con clips de 4 segundos y 20 pasos de inferencia para la mejor relación calidad-velocidad en tarjetas de 8-16GB.
De 720p a 4K: El RTX Video Upscaler
Aquí es donde el pipeline se vuelve inteligente. No generas a 4K — generas a 720p y escalas a 4K en segundos usando el nuevo nodo RTX Video de NVIDIA integrado directamente en ComfyUI.
El RTX Video upscaler se ejecuta en tiempo real, aprovechando hardware dedicado en las GPUs RTX para afilar bordes, limpiar artefactos de compresión y producir una salida 4K nítida. Este enfoque de dos pasos (generar a 720p, escalar a 4K) es dramáticamente más eficiente que forzar la generación en 4K, y la diferencia de calidad es insignificante.
Para equipos creativos que producen contenido para redes sociales, creatividades publicitarias o videos de producto, esto significa que puedes iterar rápidamente a baja resolución y solo escalar tus selecciones finales — un flujo de trabajo que replica cómo los editores de video profesionales ya trabajan.
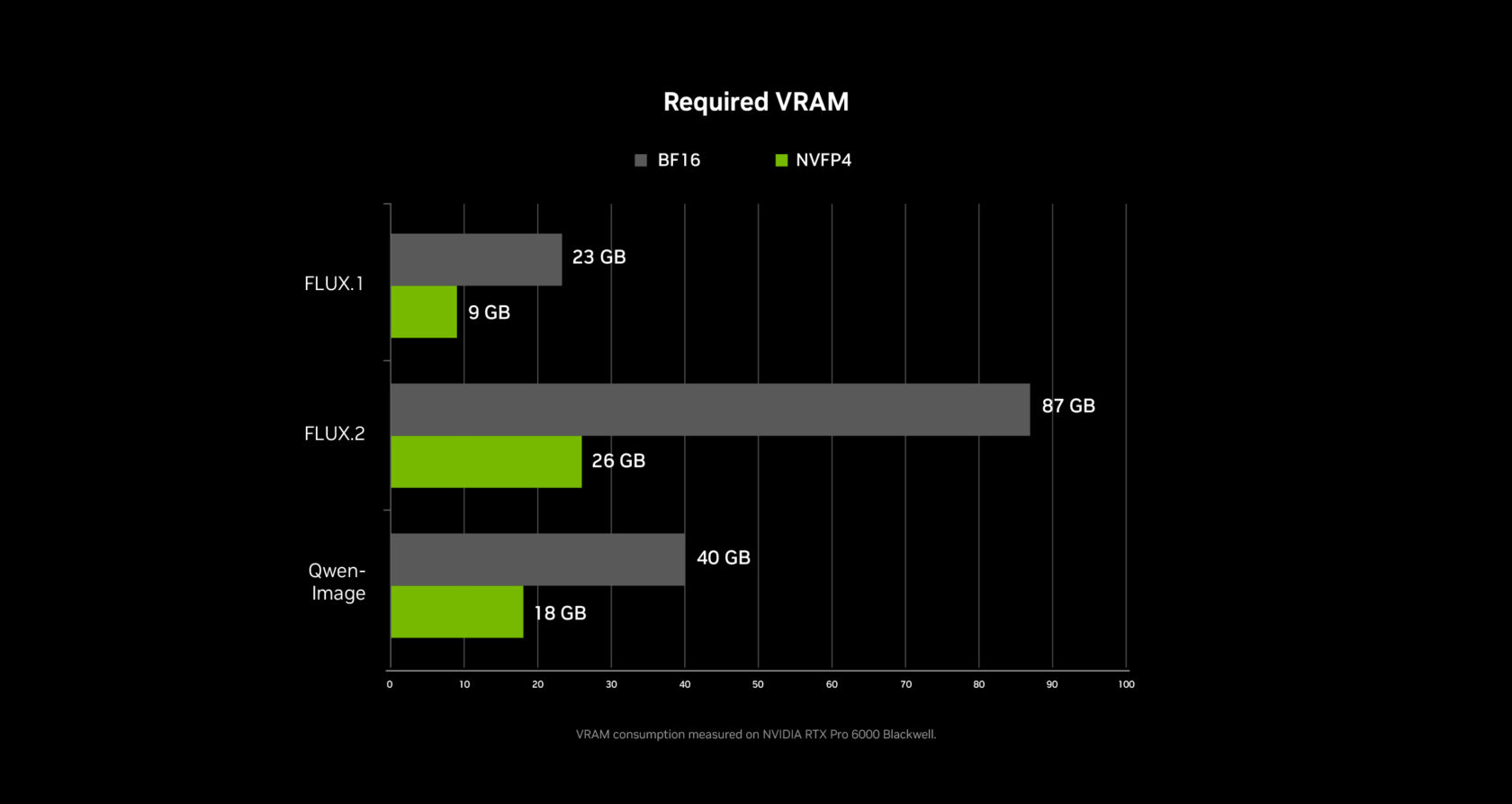
Weight Streaming: Rompiendo la Barrera de VRAM
Una de las innovaciones más prácticas es el weight streaming, una colaboración entre NVIDIA y ComfyUI que permite al sistema descargar los pesos del modelo a la RAM del sistema cuando la VRAM de la GPU se agota.
Esto significa que una RTX 4070 de gama media con 12GB de VRAM puede ejecutar grafos de nodos complejos de múltiples etapas que normalmente requerirían 24GB+. La generación es más lenta cuando el streaming se activa, pero funciona — y para agencias que no pueden justificar una GPU de $2,000 para cada miembro del equipo, esto hace que el video IA local sea accesible para todo el equipo.
| Nivel de GPU | VRAM | Configuración Recomendada |
|---|---|---|
| RTX 5090 / 5080 | 24-32GB | 720p24, clips de 4 segundos, 20 pasos |
| RTX 4080 / 4070 Ti | 12-16GB | 540p24, clips de 4 segundos, 20 pasos |
| RTX 4060 / 4070 | 8-12GB | 540p24, weight streaming activado |
El Pipeline de Blender: Control 3D Encuentra a la Generación IA
NVIDIA también introdujo un pipeline impulsado por RTX que integra Blender con la generación de video IA. En lugar de depender únicamente de prompts de texto — que te dan control limitado sobre composición y movimiento de cámara — los artistas pueden configurar escenas 3D en Blender, definir keyframes y usarlos como entradas de control para LTX-2.
Este enfoque híbrido da a los directores creativos algo que el texto-a-video nunca pudo: precisión a nivel de fotograma. Define tus ángulos de cámara, posiciones de personajes e iluminación en Blender, y luego deja que la IA se encargue de las texturas, el movimiento y los detalles atmosféricos. Es lo mejor de ambos mundos.
"La integración con Blender da a los directores creativos lo que el texto-a-video nunca pudo — control a nivel de fotograma sobre cada toma."
Qué Significa Esto para los Equipos Creativos
El cambio hacia la generación local de video IA no se trata solo de ahorrar en costos de nube (aunque eso es significativo). Cambia el proceso creativo de maneras fundamentales:
- Privacidad y protección de PI — Los activos y conceptos de clientes nunca salen de tu máquina. Para agencias que manejan campañas confidenciales, esto elimina una preocupación importante con las herramientas basadas en la nube.
- Iteración ilimitada — Sin tarifas por generación significa que tu equipo puede experimentar libremente. Genera 50 variaciones de una escena sin ver cómo se disparan los costos.
- Capacidad offline — Produce video IA en un avión, en las oficinas de un cliente o en cualquier lugar sin internet confiable.
- Integración en pipelines — Las herramientas de generación local ahora exponen APIs y protocolos que se conectan directamente a plataformas de orquestación, habilitando flujos de trabajo automatizados desde el concepto hasta el clip final en 4K.
Pero aquí está el desafío: la generación local es solo una pieza del rompecabezas. La mayoría de los equipos creativos usan una mezcla de modelos locales y en la nube — LTX-2 para iteración rápida, Runway o Kling para estilos específicos, Sora para secuencias cinematográficas. Gestionar esa realidad multi-modelo manualmente es donde el cuello de botella se desplaza.
Dónde Encaja XainFlow: Orquestando el Pipeline Completo
Este es exactamente el problema que XainFlow resuelve. En lugar de forzar a los equipos a elegir entre local y nube, XainFlow actúa como la capa de orquestación que une todo.
A través de la API y el protocolo MCP de XainFlow, los equipos creativos pueden construir flujos de trabajo que:
- Dirigen solicitudes de generación al mejor modelo para cada tarea — LTX-2 local para prototipado rápido, modelos en la nube para renders de producción final
- Encadenan pasos de generación automáticamente — genera un clip base localmente, aplica transferencia de estilo vía un modelo en la nube, escala a 4K, todo en un pipeline automatizado
- Ejecutan operaciones por lotes a través de múltiples modelos simultáneamente — produce 20 variaciones de una escena en diferentes motores de IA sin cambiar de herramienta
- Mantienen consistencia de marca incrustando activos de referencia, guías de estilo y parámetros de calidad directamente en plantillas de flujo de trabajo reutilizables
"El verdadero poder no está en ningún modelo de IA individual — está en la capa de orquestación que permite a los equipos creativos usar todos sin fricciones."
Con la generación local volviéndose tan rápida y accesible, los equipos que ganen no serán los que tengan la mejor GPU — serán los que tengan los mejores flujos de trabajo. XainFlow te da la infraestructura para construir esos flujos de trabajo una vez y escalarlos en cada proyecto.
XainFlow se conecta a herramientas de generación local como ComfyUI junto con modelos en la nube a través de una API unificada e integración MCP. Construye pipelines creativos automatizados que aprovechan lo mejor de ambos mundos. Aprende más en docs.xainflow.com.
El Panorama General
La brecha entre los servicios de video IA en la nube y la generación local se ha cerrado más rápido de lo que cualquiera esperaba. Con LTX-2, aceleración de hardware RTX y pipelines optimizados, los equipos creativos ahora tienen un estudio de video IA en 4K listo para producción debajo de sus escritorios.
Pero los equipos más inteligentes no están eligiendo entre local y nube — están construyendo pipelines orquestados que usan ambos estratégicamente. Local para velocidad, privacidad e iteración. Nube para modelos especializados y máxima calidad. Y una plataforma como XainFlow para conectarlo todo en flujos de trabajo que escalan.
La pregunta no es si el video IA local es viable. Es si tu equipo tiene la infraestructura para aprovecharlo junto con todo lo demás.


